Redis很“忙” 作者: 灯小笼 时间: 2018-09-04 分类: 架构 最近redis很“忙”,一到上午10点左右,redis就频繁出现各种报错,大部分的场景还好,我们对cache的异常进行了捕获,只是在日志里边记录一下,而不会抛出异常,所以顶多就慢一些而已。不过,还是有让我们也不得不忙的场景出来: 1、有的场景使用redis缓存校验码,比如用户通过手机验证码登录时,明明发送验证码成功,明明输入正确的验证码,但是就是提示验证失败。 2、随着每个依赖redis的服务不断变慢,网站不断出现502,最后,基本上不能访问了。 于是,运维人员不得不一声令下,重启redis。终于,作为cache的redis内存占用量急剧下降,连接数也迅速降低,网站也很快恢复稳定,一切似乎完美地回归了。 这样的事情重复了几天,大家找到规律了,于是索性定了个定时任务,每天凌晨5点的时候,重启一下redis,为即将躁动的10点偃旗息鼓,杀杀他的威风。 不过,作为有技术素养有技术追求的团队,怎么能这样就认怂了呢? <!--more--> cache方面的问题: 1、php生成的cache存储量很大(超过1G),且持续增长。 2、每天10点左右会出现redis连接数激增。 出现严重问题的现场一般是这样的:cache内存使用量超过1G,且连接数在较高水平,大部分缓存读取不到,写入不了,从而导致整个网站访问极慢。而一旦redis读取不到,就会一直试图写入,而写入又不能成功,下次读取依然失败,如此往复,导致写操作比正常时候要多很多,形成雪崩,最终导致redis完全不能工作,引起整个网站都不能正常访问了。 重启后,由于redis未配置持久化,使用内存量急剧降低,cache的写操作恢复正常,写操作显著减少,因此cache上的连接数也会明显减少。不过,大概在一两天的周期内,redis使用内存量又会逐步恢复到原有水平。 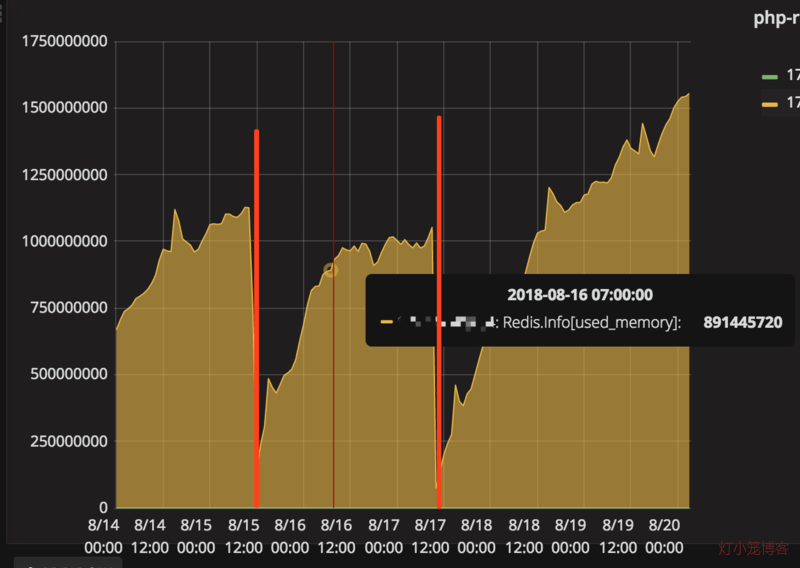 针对这个现象,我们做了一些尝试,比如,原来redis用来做cache和做队列用的是同一个实例,我们把它们分开了;对redis使用长连接等,不过,收效甚微,没有从根本上解决问题。于是,我们开始回到出发点,解决这样一个问题:我们用redis到底做了什么。 茫茫cache海,不知道从哪下手,所以,还是先找主要问题,再研究次要问题。 ## 单一大key `redis-cli`提供了一个查找大key的简单命令: ```bash redis-cli --bigkeys ``` 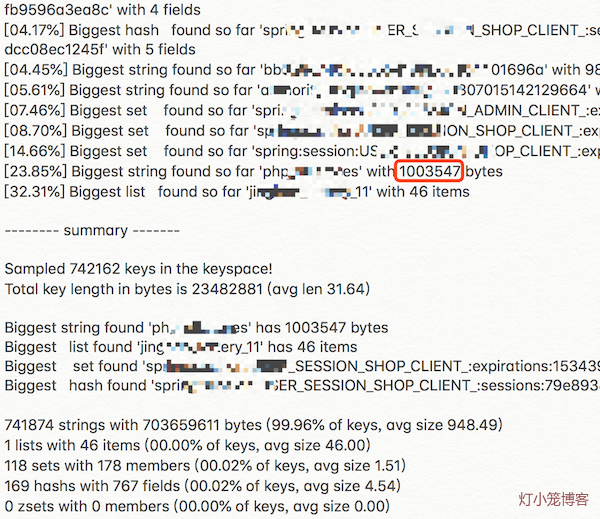 最大的key的尺寸为1003547byte,约980k。而这个key的是在app搜索商家名称时调用,调用频率还蛮大,也没有在客户端做缓存。通过kibana,可以查到这个和这个cache相关的接口峰值调用频率每30分钟近500多次,属于又大又热的key了。 除了这个异常突出的key意外,剩下的最大的key也就是150k、95k、90k这样的水平了,因此,当下最主要的目标是先行消灭这个最大的始作俑者。 考虑到这个api接口被app使用,如果做大的调整,必须要重新发布app才行,因此我们对接口输出的内容进行了过滤,只保留app用到的数据。经过一番调整以后,重新发布接口,cache的内容马上变小很多,整体响应的时间也加快了。  综合上图分析,我们从redis存储大小、接口文本长度、响应速度三方面进行分析。 | 维度 | 改进前 | 改进后 | 变化率 | |-------------|--------|-------|--------| | redis存储大小 | 980k | 437k | -55.4% | | 接口文本长度 | 5302k | 969k | -81.7% | | 响应速度 | 700ms | 40ms | -94.2% | 可见,整体的提升还是蛮大的。 这是最大的key,改进以后,对这个接口的影响很大,但是从整体而言,并没有对cache的情况做出显著的改变。我们还得继续探索。 另外,通过对源代码的排查,还发现了对redis的读写超时时间这个配置并没有实际生效。我们在配置中配置的超时时间是100ms,而这种大key,读写时间早就过了100k,但是还能正常读取下来,也就拜这点所赐。由于超时时间没有生效,读取大key的时候,时间会被拉长,对redis资源的占用时间也会变长,进而影响其他使用redis资源的连接的效率,从而在整体上拉低了redis的服务能力。 ## 系列大key 除了单一大key,还有系列大key。所谓“系列大key”,是指存储的一系列同种性质内容的key,它们的key名称前缀一致,最后的特征id会不一样。比如:post_1111、post_1112、post_1233这样的key。虽然它们单个的key占用的空间不大,但是胜在数量多,读写频繁,甚至于只读不写,实际命中率非常低。 这是我们在分析往redis里边存储进入的key时发现的问题。我们通过`tcpflow`抓包,获取到redis正在写入的key: ```bash tcpflow port 6379 -cp -i ens192|grep SET -A 2 > setcache.log ``` 这样抓取一段时间后,我们对里边具体存入的key的使用频率做了一下统计,从而知道哪些key比较活跃。接下来就需要知道这些key具体存储什么内容,做什么用的,大概长度是多少,才好做进一步的处理措施。 为了解决这几个问题,我们写了几个简单的工具: 1. 根据key获取对应内容。这是因为长度较大的缓存项会被压缩,需要通过工具还原。 2. 根据key的前缀获取全部的key列表,并累加每个key的对应的长度,计算总的存储大小和平均大小。 通过redis的KEYS方法,可以找出前缀特定的key出来,如: ``` redis-cli KEYS prefix* ``` 那么,怎么计算每个缓存项的长度呢?既然redis-cli可以知道哪个key最大,因此里边一定可以找到真相。因此,笔者查阅了一下redis-cli的[源码][1],果然有我们需要的答案。 ```c static void getKeySizes(redisReply *keys, int *types, unsigned long long *sizes) { redisReply *reply; char *sizecmds[] = {"STRLEN","LLEN","SCARD","HLEN","ZCARD"}; unsigned int i; /* Pipeline size commands */ for(i=0;i<keys->elements;i++) { /* Skip keys that were deleted */ if(types[i]==TYPE_NONE) continue; redisAppendCommand(context, "%s %s", sizecmds[types[i]], keys->element[i]->str); } ... ``` 每种数据类型都有对应计算长度的函数,我们使用redis作为缓存的时候,实际上都是序列化成文本后存起来的,因此使用`STRLEN`就能查找到每个key对应的存储大小了。 我们的工具大致如下: ```php #! /bin/env php <?php $key = $argv[1]; $redis = new \Redis(); $redis->connect('172.16.0.1', 6379); $keys = $redis->keys($key); $num = count($keys); if ($num == 0) { echo "found none.\n"; exit(0); } echo "found $num keys.\n"; $total = 0; foreach($keys as $i => $key) { $total += $redis->strlen($key); if ($i % 1000 == 0) { echo $i.":".$total."\r"; } } $redis->close(); printf("\navarage size:%.2fk", $total/$num/1024); printf("\ntotalsize:%.2fM", $total/1024/1024); echo PHP_EOL; ``` 通过这些工具,经过对实时写入的cache的key的进一步分析,最后找到几个重要的系列大key。 | key | 数量 | 平均大小 | 总大小 | |---------------------|--------|-------|--------| | php_newGetTopic* | 131393 | 2.73k | 350.78M | | php_bbs_posts* | 144066 | 1.51k | 212.22M | | php_getAskPostList* | 39155 | 1.61k | 61.75M | | 合计 | 314614 | - | 624.75M | 这样一看,吓了一跳,总共1G多的缓存项,这几个系列的大key就占据了半壁江山。为什么会这样呢? 查看这些key对应的缓存内容就知道了,它们主要用来存储帖子和问答的内容及回答。这些内容虽然现在已经很不活跃了,但是确实爬虫的最爱。而且,爬虫会顺藤摸瓜,一篇一篇爬从不怕累。我们查看了一下缓存过期时间,一般都被设置了一天以上。而真实的情况是,一天之内大部分的内容就只有爬虫经过一次,缓存再也没有发挥作用了,因此这样的缓存的命中率总是为0。另外,作为帖子而言,内容都比较长,加上量一大,占的空间自然就多了。 再一分析,这些缓存一般都是通过主键就可以关联到的数据,从数据库查的效率也很高的。加上命中率太低,索性不如去掉。 ... 经过一番代码改造,发布上线,终于,我们预期的效果出来了,看看图片就知道有多美。 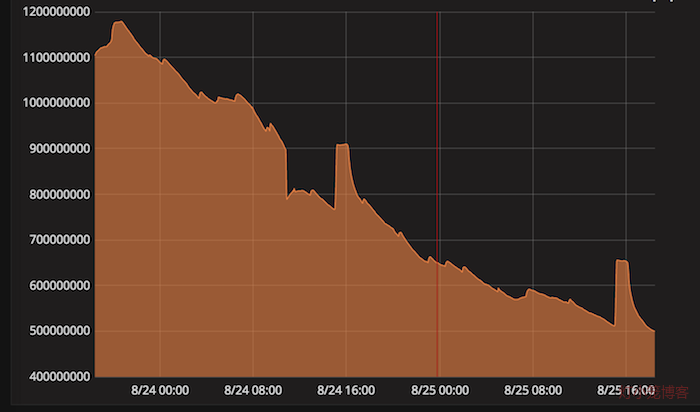 经过几天的过渡,我们的缓存量终于回到了300M左右,整体运行平稳,连接数维持较低水平,抖动很小,再也没有出现过之前的繁忙景象了。 ## 总结 ### cache问题查找流程 1. 检查cache的存储量的变化规律 如果一直增加,可以通过查找哪些key增加得比较多,过期时间比较长,存储内容比较大 2. 分析cache出问题时的存储量和连接数的关系 如果总的存储量大,可以考虑增加cache实例。 如果连接数过多,且使用了短连接,导致TIME_WAIT数量过大,可以考虑使用长连接连接cache。 3. 查找cache的大key ```bash redis-cli --bigkeys ``` 4. 检查大key里边是否有带有变量(如数字id)的key。 如果有,查找此类key的数量,考察这些key的命中率,尽量只缓存关键的主键。通过查找主键即可找出的内容,直接从db查找即可,不需要缓存。 ### 规范问题 cache除了问题才去查找原因的模式,虽然有效但总归有些滞后,还是需要有提前的预估,需要配合规范和制度,从根源上保障缓存使用的合理化,并使得对缓存使用合理性有据可查,有据可依。 通过这次的查找问题,后面对于缓存的使用可以从这几个方面进行规范: 1. key长度不宜过长,不宜用md5作为key。 2. key应该见名知意,表达真实意图。 3. value不宜过大,最好能限制在10k甚至更低的大小内(经验值,后面再做考证)。太大网络传输速度受到影响。 4. value用来存储关键性的id及关系等,基于主键对应的对象直接通过db检索即可。 5. 只用来缓存热点数据,提升缓存命中率。 最后,再来一篇引申的阅读:《[阿里云Redis开发规范][2]》。 [1]: https://github.com/antirez/redis/blob/unstable/src/redis-cli.c [2]: https://yq.aliyun.com/articles/531067 标签: redis
您好,我是开发者头条的运营。感谢您的辛苦创作。您的《Redis很“忙”》已被我们平台用户推荐到首页。为了让更多读者认识您,我们邀请您来开发者头条分享。与创作不同,您仅需复制粘贴文章链接即可完成分享。可以在各大应用市场搜索 “开发者头条” 找到我们的应用,欢迎了解。期待您的分享。
学到了
感谢站长分享。